 `
`



Project Overview
In this project, I developed a convoluted neural network to recognize American Sign Language (ASL) characters from images. I conducted extensive research and implemented the model architecture with some inspiration of which layers to use from the Sign Language Classification project. Leveraging my prior knowledge from my WINLAB ML research internship, I applied machine learning techniques to build something that I found very interesting and practical.
Learning
Libraries Used:
- NumPy: Used for numerical operations, particularly for handling arrays and matrices efficiently.
- Pandas: Used for data manipulation and analysis, mainly for organizing the image file paths and labels into a DataFrame.
- Matplotlib and Seaborn: Used for data visualization, helping to understand the distribution of images by ASL sign and providing insights into the dataset.
- PIL (Python Imaging Library): Used for image loading and preprocessing tasks.
- Keras (with TensorFlow backend): Keras is a high-level neural networks API that provides an easy-to-use interface for building and training deep learning models. TensorFlow is the underlying backend used for computations.
Throughout this project, I gained valuable insights and learned several key concepts:
Data Preprocessing: I learned how to load and preprocess images which is an essential step in building machine learning models. I learned how to resize, recolor, and transform images to be readable data which can be inputted into the model.
Model Architecture: I researched and implemented a Convolutional Neural Network (CNN) architecture, understanding the purpose and functionality of each layer. I decided on using a Sequential model as I believed that it would give me the most insight and opportunity to learn about the uses of each layer. This included convolutional layers for feature extraction, pooling layers for down-sampling, dense layers for classification, and activation functions for introducing non-linearity. During my research I found a similar project which I decided to take inspiration from for my own image classifciation project.
Training Process: I learned how to compile and train the model using appropriate optimization algorithms, loss functions, and evaluation metrics. I also implemented callbacks for monitoring training progress and preventing overfitting.
Model Evaluation: I evaluated the model's performance using accuracy and loss metrics on both training and validation datasets. This helped me understand the model's effectiveness and identify areas for improvement. I mostly used matplotlib and numpy to make charts to gauge the success of each of the metrics I changed.
Data Visualization
Description: I visualized the distribution of images by ASL sign in the dataset. Using Matplotlib and Seaborn libraries, I created a bar plot showing the count of images for each ASL sign. This visualization helped me understand the dataset's composition and ensure that it was well-balanced across different signs.
Significance: Visualizing the data distribution is essential for understanding the dataset's characteristics. It ensures that the model training process is not biased towards certain signs due to imbalanced data, which could affect the model's performance.
Model Architecture
model = Sequential()
model.add(Conv2D(32, (5, 5), activation='relu', input_shape=(image_size, image_size, 3)))
model.add(MaxPooling2D(padding='same'))
model.add(Conv2D(64, (5, 5), activation='relu'))
model.add(MaxPooling2D(padding='same'))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(36, activation='softmax'))
model.summary()
Description: Here, I provided an overview of the model architecture used for ASL recognition. The architecture consists of convolutional layers followed by max-pooling layers for feature extraction and down-sampling. The flattened output is then fed into fully connected layers with ReLU activation functions for classification, followed by a softmax layer for multi-class classification.
Significance: Understanding the model architecture is crucial for designing an effective ASL recognition system. Each layer serves a specific purpose in extracting and transforming input data, ultimately leading to accurate predictions.
Training Progress
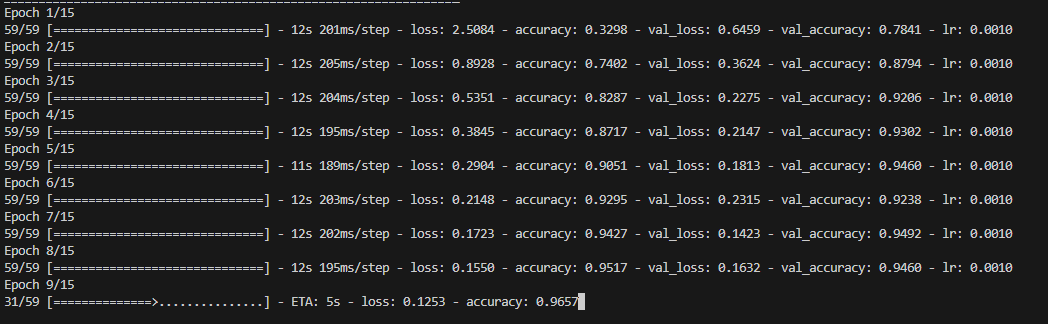
Description: Using training and validation accuracy and loss metrics, I monitored the model's performance during the training process. Early stopping and learning rate reduction callbacks were employed to prevent overfitting and improve convergence.
Significance: Tracking the training progress helps assess the model's convergence and performance over time. It allows for early detection of overfitting or underfitting issues and guides adjustments to hyperparameters or model architecture to optimize performance.
Model Evaluation
Description: I evaluated the model's performance on both training and validation datasets. Using accuracy and loss metrics, I assessed the model's ability to correctly classify ASL signs. The evaluation provided insights into the model's effectiveness and generalization capability.
Significance: Model evaluation is critical for assessing its performance and identifying areas for improvement. By comparing training and validation metrics, I could detect potential issues such as overfitting or underfitting and adjust the model accordingly.
Future Work
Description: Looking ahead, I plan to extend the project by implementing real-time ASL character recognition using a camera or video feed. This will involve integrating computer vision techniques to preprocess live video streams and applying the trained model for real-time prediction. Additionally, I aim to explore methods for improving the model's accuracy and efficiency in real-world scenarios.
Significance: Real-time ASL recognition has practical applications in assistive technology and human-computer interaction. By enabling users to interact with devices using sign language, it promotes accessibility and inclusivity for individuals with hearing impairments. Continuing to enhance the model's capabilities will contribute to advancing assistive technologies and improving communication accessibility.